Texture Gathers and Coordinate Precision
A few years ago I came across an interesting problem. I was trying to implement some custom texture filtering logic in a pixel shader. It was for a shadow map, and I wanted to experiment with filters beyond the usual hardware bilinear.
I went about it by using texture gathers to retrieve a neighborhood of texels, then
performing my own filtering math in the shader. I used frac on the scaled texture coordinates to
figure out where in the texel I was, emulating the logic the GPU texture unit would have used to
calculate weights for bilinear filtering.
To my surprise, I noticed a strange artifact in the resulting image when I got the camera close to a surface. A grid of flickery, stipply lines appeared, delineating the texels in the soft edges of the shadows—but not in areas that were fully shadowed or fully lit. What was going on?

Dramatic reenactment of the artifact that started me on this investigation.
After some head-scratching and experimenting, I understood a little more about the source of these errors. In the affected pixels, there was a mismatch between the texels returned by the gather and the texels that the shader thought it was working with.
You see, the objective of a gather operation is to retrieve the set of four texels that would be used for bilinear filtering, if that’s what we were doing. You give it a UV position, and it finds the 2×2 quad of texels whose centers surround that point, and returns all four of them in a vector (one channel at a time).
As the UV position moves through the texture, when it crosses the line between texel centers, the gather will switch to returning the next set of four texels.


In this diagram, the large labeled squares are texels. Whenever the input UV position is within the solid blue box, the gather returns texels ABCD. If the input point moves to the right and crosses into the dotted blue box, then the gather will suddenly start returning BEDF instead. It’s a step function—a discontinuity.
Meanwhile, in my pixel shader I’m calculating weights for combining these texels according to some filter. To do that, I need to know where I am within the current gather quad. The expression for this is:
float2 texelFrac = frac(uv * textureSize - 0.5);
(The - 0.5 here is to make coordinates relative to texel centers instead of texel edges.)
This frac is supposed to wrap around from 1 back to 0 at the exact same place where the gather switches
to the next set of texels. The frac has a discontinuity, and it needs to match exactly with the
discontinuity in the gather result, for the filter calculation to be consistent.
But in my shader, they didn’t match. As I discovered, there was a region—a very small
region, but large enough to be visible—where the gather switched to the next set of texels
before the frac wrapped around to 0. Then, the shader blithely made its weight calculations for
the wrong set of texels, with ugly results.
 and gather (yellow)")
 and gather (yellow)")
This diagram is not to scale—the actual mismatch is much smaller than depicted here—but it illustrates what was going on. It was as if the texel squares as judged by the gather were the yellow squares, ever so slightly offset from the blue ones that I got by calculating directly in the shader. Those flickery lines in the shadow will make their entrance whenever some pixels happen to fall into the tiny slivers of space between these two conflicting accounts of “where the texel grid is”.
Now on the one hand, this suggests a simple fix. We can add a small offset to our calculation:
const float offset = /* TBD */;
float2 texelFrac = frac(uv * textureSize + (-0.5 + offset));
Then we can empirically hand-tweak the value of offset, and see if we can find a value that makes
the artifact go away.
On the other hand, we’d really like to understand why this mismatch exists in the first place. And
as it turns out, once we understand it properly, we’ll be able to deduce the exact, correct value
for offset—no hand-tweaking necessary.
Into the Texture-Verse
Texture gathers and samples are performed by a GPU’s “texture units”—fixed-function hardware blocks that shaders call out to. From a shader author’s point of view, texture units are largely a black box: put UVs in, get filtered results back. But to address our questions about the behavior of gathers, we’ll need to dig down a bit into what goes on inside that black box.
We won’t (and can’t) go all the way down to the exact hardware architecture, as those details are proprietary, and GPU vendors don’t share a lot about them. Fortunately, we won’t need to, as we can get a general logical picture of what’s happening on the basis of formal API specs, which all the vendors’ texture units need to comply with.
In particular, we can look at the Direct3D functional spec (written for D3D11, but applies to D3D12 as well), and the Vulkan spec. We could also look at OpenGL, but we won’t bother, as Vulkan generally specifies GPU behavior the same or more tightly than OpenGL.
Let’s start with Direct3D. What does it have to say about how texture sampling works?
Quite a bit—that’s the topic of a lengthy section, §7.18 Texture Sampling. There are numerous steps described for the sampling pipeline, including range reduction, texel addressing modes, mipmap selection and anisotropy, and filtering. Let’s focus in on how the texels to sample are determined in the case of (bi)linear filtering:
D3D §7.18.8 Linear Sample Addressing
…Linear sampling in 1D selects the nearest two texels to the sample location and weights the texels based on the proximity of the sample location to them.
- Given a 1D texture coordinate in normalized space U, assumed to be any float32 value.
- U is scaled by the Texture1D size, and 0.5f is subtracted. Call this scaledU.
- scaledU is converted to at least 16.8 Fixed Point. Call this fxpScaledU.
- The integer part of fxpScaledU is the chosen left texel. Call this tFloorU. Note that the conversion to Fixed Point basically accomplished: tFloorU = floor(scaledU).
The right texel, tCeilU is simply tFloorU + 1.
…
The procedure described above applies to linear sampling of a given miplevel of a Texture2D as well…
OK, here’s something interesting: “scaledU is converted to at least 16.8 Fixed Point.” What’s that about? Why would we want the texture sample coordinates to be in fixed-point, rather than staying in the usual 32-bit floating-point?
One reason is uniformity of precision. Another section of the D3D spec explains:
D3D §3.2.4 Fixed Point Integers
Fixed point integer representations are used in a couple of places in D3D11…
- Texture coordinates for sampling operations are snapped to fixed point (after being scaled by texture size), to uniformly distribute precision across texture space, in choosing filter tap locations/weights. Weight values are converted back to floating point before actual filtering arithmetic is performed.
As you may know, floating-point values are designed to have finer precision when the value is closer to 0. That means texture coordinates would be more precise near the origin of UV space, and less elsewhere. However, image-space operations such as filtering should behave identically no matter their position within the image. Fixed-point formats have the same precision everywhere, so they are well-suited for this.
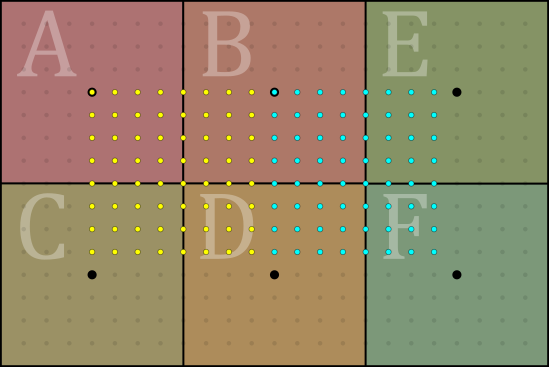
Illustration of fixed-point texture coordinates, if there were only 3 subpixel bits (23 = 8 subdivisions). Each dot is a possible fixed-point value. Two adjacent bilinear/gather footprints are highlighted in yellow and cyan.
Illustration of fixed-point texture coordinates, if there were only 3 subpixel bits (23 = 8 subdivisions). Each dot is a possible fixed-point value. Two adjacent bilinear/gather footprints are highlighted in yellow and cyan.
(Incidentally, you might wonder: don’t we already have non-uniform precision in the original float32 coordinates that the shader passed into the texture unit? Yes—but given current API limits on texture sizes, the 24-bit float mantissa gives precision equal or better than 16.8 fixed-point, throughout at least the [0,1]² UV rectangle. You can still lose too much precision if you work with too-large UV values in float32 format, though.)
Another possible reason for using fixed-point in texture units is just that integer ALUs are smaller and cheaper than floating-point ones. But there are a lot of other operations in the texture pipeline still done in full float32 format, so this likely isn’t a major design concern.
Precision, Limited Edition
At this point, we can surmise that our mysterious gather discrepancy may have something to do with coordinates being converted to “at least 16.8 fixed point”, per the D3D spec.
These are the scaled texel coordinates, so the integer part of the value (the 16 bits in front of the radix point) determines which texels we’re looking at, and then there are at least 8 more bits in the fractional part, specifying where we are within the texel.
The minimum 8 bits of sub-texel precision is also re-stated in various other locations in the spec, such as:
D3D §7.18.16.1 Texture Addressing and LOD Precision
The amount of subtexel precision required (after scaling texture coordinates by texture size) is at least 8-bits of fractional precision (28 subdivisions).
The D3D spec text is also clear that conversion to fixed-point occurs before taking the integer part of the coordinate to determine which texels are filtered.
But how does this end up inducing a tiny offset to the locations of texel squares, when we compare the 32-bit float inputs to the fixed-point versions?
There’s one more ingredient we need to look at it, which is how the conversion to fixed-point is accomplished. Specifically: how does it do rounding? The 16.8 fixed-point has coarser precision than the input floats in most cases, so floats will need to be snapped to one of the available 16.8 values.
Back to our best friend, the D3D spec, which gives detailed rules about the various numeric formats, the arithmetic rules they need to satisfy, and the processes for conversion amongst them. Regarding conversion of floats to fixed-point:
D3D §3.2.4.1 FLOAT -> Fixed Point Integer
For D3D11 implementations are permitted 0.6f ULP tolerance in the integer result vs. the infinitely precise value n*2^f after the last step above.
The diagram below depicts the ideal/reference float to fixed conversion (including round-to-nearest-even), yielding 1/2 ULP accuracy to an infinitely precise result, which is more accurate than required by the tolerance defined above. Future D3D versions will require exact conversion like this reference.
[in the “float32 -> Fixed Point Conversion” diagram:]
- Round the 32-bit value to a decimal that is extraBits to the left of the LSB end, using nearest-even.
There’s the answer: the conversion uses rounding to nearest-even (the same as the default mode for float math). This means floating-point values will be snapped to the nearest fixed-point value, with ties breaking to the even side.
Now, we’re finally in a position to explain the artifact that started this whole quest. When we pass our float32 UVs into the texture unit, they get rounded to the nearest fixed-point value at 8 subpixel bits—in other words, the nearest 1/256th of a texel. This means that the last half a bit—the last 1/512th of a texel—will round up to the next higher integer texel value.
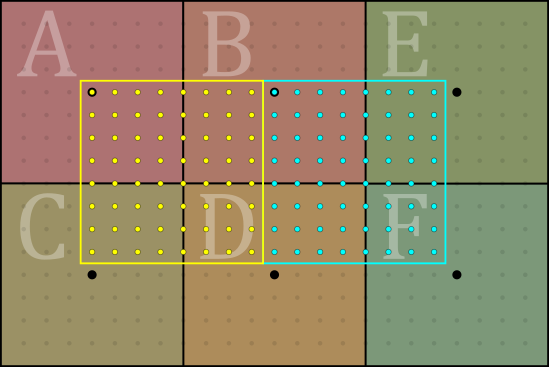
When fixed-point conversion is done by round-to-nearest, all the points in the yellow square end up rounded to one of the yellow dots, and assigned the corresponding set of texels; likewise the cyan ones.
Note how the squares are offset from the texel centers by half the grid spacing.
When fixed-point conversion is done by round-to-nearest, all the points in the yellow square end up rounded to one of the yellow dots, and assigned the corresponding set of texels; likewise the cyan ones.
Note how the squares are offset from the texel centers by half the grid spacing.
Therefore, in that last 1/512th, bilinear filtering operations and gathers will choose a one-higher
set of texels to interpolate between—while the shader computing frac on the original float32
values will still think it’s in the original set of texels. This is exactly what we saw in
the original artifact!
Accordingly, we can now see that the frac input needs to be shifted by exactly 1/512th texel in
order to make its wrap point line up. It’s very much like the old C/C++ trick of adding 0.5 before
converting a float to integer, to obtain rounding instead of truncation.
const float offset = 1.0/512.0;
float2 texelFrac = frac(uv * textureSize + (-0.5 + offset));
Lo and behold, the flickery lines on the shadow are now completely gone. 👌🎉😎
Eight is a Magic Number
All GPUs that support D3D11—which means essentially all PC desktop/laptop GPUs from the last decade and a half—should be compliant with the D3D spec, so they should all be rounding and converting their texture coordinates the same way. Except that there’s still some wiggle room there: the spec only prescribes 8 subtexel bits as a minimum. GPU designers have the option to use more than 8, if they wish. How many bits do they actually use?
Let’s see what Vulkan has to say about it. The Vulkan spec’s chapter
§16 Image Operations
describes much the same operations as the D3D spec, but at a more abstract mathematical level—it
doesn’t nail down the exact sequence of operations and precision the way D3D does. In particular,
Vulkan doesn’t say what numeric format should be used for the floor operation that extracts the
integer texel coordinates. However, it does say:
VK §16.6 Unnormalized Texel Coordinate Operations
…the number of fraction bits retained is specified by
VkPhysicalDeviceLimits::subTexelPrecisionBits.
So, Vulkan doesn’t out-and-out say that texture coordinates should be converted to a fixed-point format, but that seems to be implied or assumed, given the specification of a number of “fraction bits” retained.
Also, in Vulkan the number of subtexel bits can be queried in the physical device properties.
That means we can use Sascha Willems’ fantastic Vulkan Hardware Database
to get an idea of what subTexelPrecisionBits values are reported for actual GPUs out there.
The results as of this writing show about 89% of devices returning 8, and the rest returning 4. There are no devices returning more than 8.
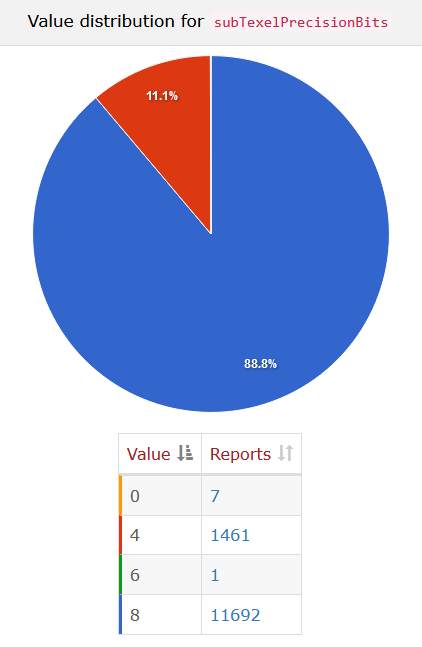
The distribution of subTexelPrecisionBits as reported by the Vulkan Hardware Database. The reports of values 0 and 6 look bogus, as do most of the reports of 4.
The Vulkan spec minimum for subTexelPrecisionBits is also 4, not 8 (see
Table 53 – Required Limits).
And it seems there’s a significant minority of GPUs that have only 4 subtexel bits. Or is there?
Let’s poke at that a little further.
Of the reports that return 4 bits, a majority of them seem to be from Apple platforms.
Now, Apple doesn’t implement Vulkan directly, so these must be going through MoltenVK.
And it turns out that MoltenVK
hardcodes subTexelPrecisionBits to 4,
at the time of this writing. The associated comment suggests that Metal doesn’t publicly
expose or specify this value, so they’re just setting it to the minimum. This value
shouldn’t be taken as meaningful!
In fact, I would bet money that all the Apple GPUs have 8 subtexel bits,
just like everyone else. (The only one I’ve tested directly is the M1, and it indeed seems to be 8.)
However, I don’t think there is any public documentation from Apple to confirm or refute this.
Many other reports of 4 subtexel bits come from older Linux drivers for GPUs that definitely have 8 subtexel bits; those might also be incomplete Vulkan implementations, or some other odd happenstance. Some Android GPUs also have both 4 and 8 reported in the database for the same GPU; I assume 8 is the correct value for those. Finally, there are software rasterizers such as SwiftShader and llvmpipe, which also seem to just return the spec minimum.
The fact that the Vulkan spec minimum is 4, rather than 8, suggests that there are (or were) some GPUs out there that actually only have 4 subtexel bits—or why wouldn’t the spec minimum be 8? But I haven’t been able to find out what GPUs those could be.
Moreover, there’s a very practical reason why 8 bits is the standard value! Subtexel precision is directly related to bilinear filtering, and most textures in 3D apps are in 8-bit-per-channel formats. If you’re going to interpolate 8-bit texture values and store them in an 8-bit framebuffer, then you need 8-bit subtexel precision; otherwise, you’re likely to see banding whenever a texture is magnified—whenever the camera gets close to a surface. Lots of effects like reflection cubemaps, skyboxes, and bloom filters would also be really messed up if you had less than 8 subtexel bits!
Overall, it seems very safe to assume that any GPU you’d actually want to run on will have exactly 8 bits of subtexel precision—no more, no less.
What about the rounding mode? Unfortunately, as noted earlier, the Vulkan spec doesn’t actually say that texture coordinates should be converted to fixed-point, and thus doesn’t specify rounding behavior for that operation.
Given that the D3D behavior is more tightly specified here, we can expect that behavior to hold whenever we’re on a D3D-supporting GPU (even if we’re running with Vulkan or OpenGL on that GPU). The question is a little trickier for other GPUs, such as Apple’s and the assorted mobile GPUs. They don’t support D3D, so they’re under no obligation to follow D3D’s spec. That said, it seems probable that they do also use round-to-nearest here, especially Apple. (I’d be a little more hesitant to assume this across the board with the mobile crowd.)
I can tell you that from my experiments, the 1/512 offset consistently fixes the gather mismatch across all desktop GPU vendors, OSes, and APIs that I’ve been able to try, including Apple’s. However, I haven’t had the chance to test this on mobile GPUs so far.
Interlude: Nearest Filtering
I initially followed a bit of a red herring with this investigation. I wanted to verify whether the 1/512 offset was correct across a wider range of hardware, so I created a Shadertoy to test it, and asked people to run it and let me know the results. (By the way, thanks, everyone!)
The results I got were all over the place. For some GPU vendors an offset was required, and for others, it wasn’t. In some cases, it seemed like it might have changed between different architectures of the same vendor. There was even some evidence that it depended on which API you were using, with D3D and OpenGL giving different results on the same GPU—although I wasn’t able to conclusively verify that. Oh jeez. What the heck?
As it turns out, I’d taken a shortcut that was actually kind of a long-cut. You see, Shadertoy is built on WebGL, which doesn’t actually support texture gathers currently (they’re planned to be in the next version of WebGL). So, I substituted with something that’s similar in many ways: nearest-neighbor filtering mode.
Just like gathers, nearest-neighbor filtering also has to select a texel based on the texture unit’s judgement of which texel square your coordinates are in, and there is again the possibility of a mismatch versus the shader’s version of the calculation. The only difference is that there isn’t a 0.5 texel offset—otherwise, I expected it to work the same way as a gather, using the same math and rounding modes.
Surprise! It doesn’t. The results of nearest-neighbor filtering suggest that GPUs aren’t consistent
in how they compute the nearest texel to the sample point. To find the nearest texel, we need to apply
floor to the scaled texel coordinates; but it looks like some GPUs round off the coordinates to
8 subpixel bits before taking the floor, and others might truncate instead of rounding—or they
might just be applying floor to the floating-point value directly, rather than converting it to
fixed-point at all.
Now, the D3D11 functional spec does say (§7.18.7 Point Sample Addressing) that point sampling (aka nearest filtering) is supposed to use the same fixed-point conversion and rounding as in the bilinear case. And some GPUs out there are definitely in violation of that, to the tune of 1/512th texel, unless I’ve misunderstood something!
Here’s the Shadertoy, if you want to check it out (see the code comments for an explanation).
Happily, however, if you’re actually interested in gathers, the behavior of those appears to be completely consistent. (Honestly, surprising for anything to do with GPU hardware!)
Conclusion
The inner workings of texture units are something we can usually gloss over as GPU programmers. For the most part, once we’ve prepared the mipmaps and configured the sampler settings, things Just Work™ and we don’t need to think about it a lot.
Once in awhile, though, something comes along that brings the texture unit’s internal behavior to the fore, and this was a great example. If you ever try to build a custom filter in a shader using texture gathers, the mismatch in the texture unit’s internal precision versus the float32 calculations in the shader will create a very noticeable visual issue.
Fortuitously, we were able to get a good read on what’s going on from a close perusal of API specs, and hardware survey data plus a few directed tests helped to confirm that gathers really do work the way it says in the spec, across a wide range of GPUs. And best of all, the fix is simple and universal once we’ve understood the problem.